Re-run stuck jobs
Observed behaviour
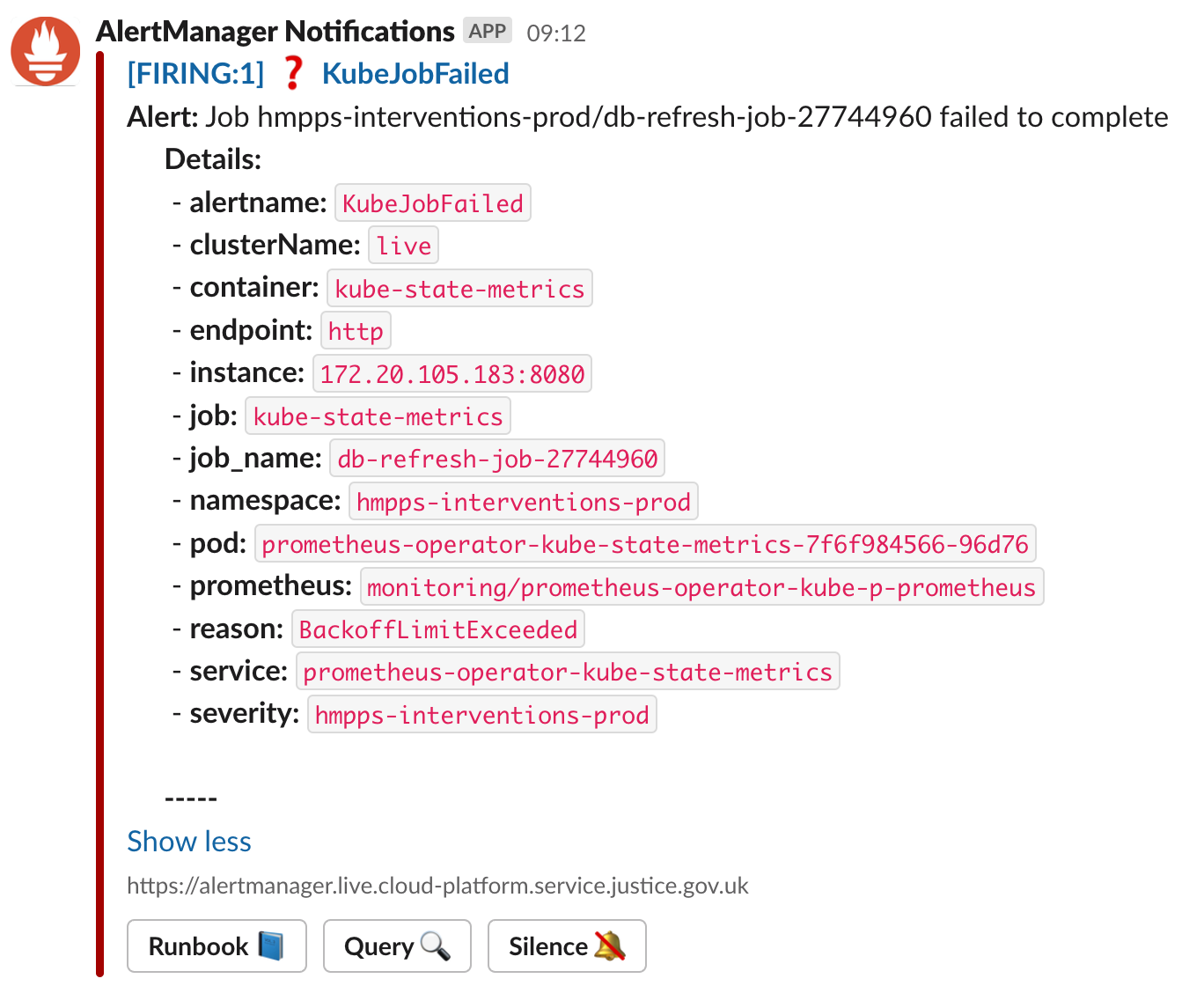
We receive a KubeJobFailed alert from AlertManager:
Checking the logs, we see a recoverable error:
$ kubectl logs --selector=job-name=db-refresh-job-27744960 --tail=-1
{snip}
pg_dump: [archiver (db)] connection to database "snip" failed: ⏎
could not translate host name "snip" to address: ⏎
Temporary failure in name resolution
Desired behaviour
We decide the error is intermittent, e.g. hostname resolution problems, and want to re-run the job.
Actions
First, get the job name:
$ kubectl get jobs --show-kind
NAME COMPLETIONS DURATION AGE
job.batch/db-refresh-job-27744960 0/1 7h9m 7h9m
Then, re-create the job with the same specs:
$ kubectl get job.batch/db-refresh-job-27744960 -o json | \
jq 'del(.spec.selector)' | \
jq 'del(.spec.template.metadata.labels)' | \
kubectl replace --force -f -
job.batch "db-refresh-job-27744960" deleted
job.batch/db-refresh-job-27744960 replaced
This page was last reviewed on 5 March 2025.
It needs to be reviewed again on 5 March 2026
by the page owner #interventions-dev
.
This page was set to be reviewed before 5 March 2026
by the page owner #interventions-dev.
This might mean the content is out of date.