Pipeline Infrastructure
This project provisions AWS Database Migration Service (DMS) resources to replicate data from source databases to Amazon S3.
This project also creates two lambda functions:
-
to validate that the DMS output is a parquet file that corresponds with expected matedata and moves it to the staging bucket if validation passes. See Validate AWS Lambda Function for more detail
-
to send notifications to slack when a DMS instance and/or task suffers from various scenarios
The diagram below summarises the resources for one database and one stack:
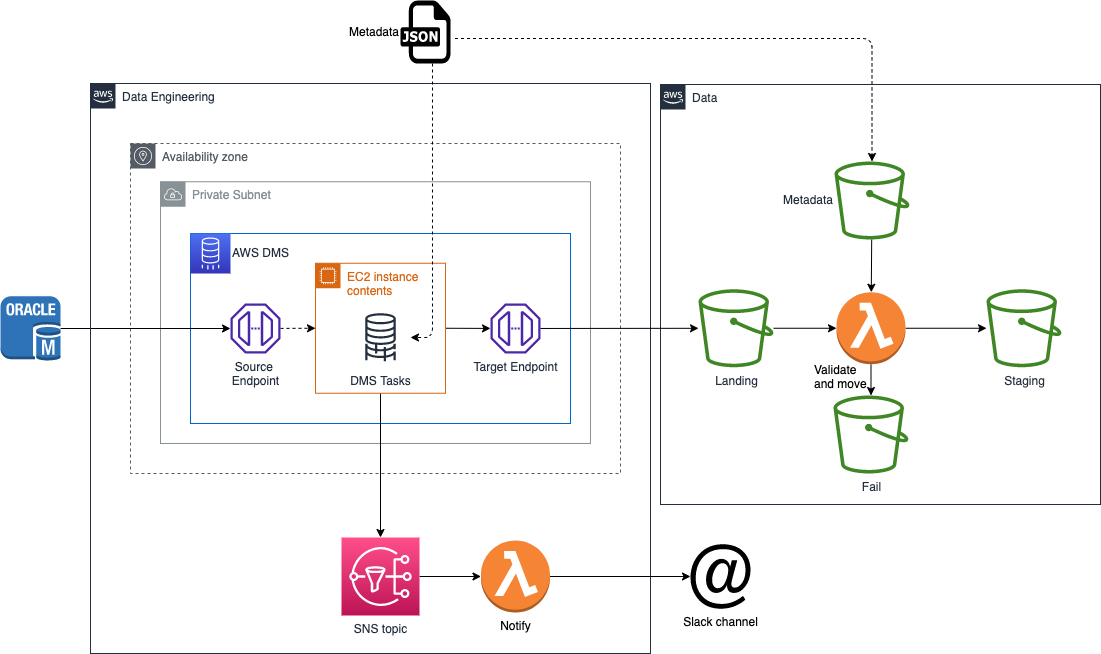
Stacks
This project contains three stacks:
pipelines-devpipelines-preprodpipelines-prod
DMS Settings
There are two ways of receiving CDC changes from Oracle database:
- Binary reader - does all the processing on the replication instance
- LogMiner - does all the processing on the source database instance
This project uses Binary Reader to limit the impact on source databases.
The DMS target is set to S3 and written to parquet files for more compact storage and faster query options. The DMS maximum batch interval size is set to 1 hour (using cdcMaxBatchInterval). This limits the number of files produced.
DMS Replication Tasks
There are three types of DMS replication tasks (see replication):
- Full-load + CDC _ Migrate existing data and replicate ongoing changes
- Full-load _ Migrate existing data
- CDC-only _ Replicate data changes only
The Full-load + CDC task is a historical artifact and not used anymore.
The tasks are configured in default_task_settings.json.
CDC changes are obtained using the Oracle redo logs which are backed up on a daily basis and the backups are kept for 1 year. They ALSO remain on disk (even after backup) until space is required, at which point the oldest are deleted. So the time they remain on disk is not fixed (typically it's around 5 days) but we can always retrieve the deleted logs from backup for up to 1 year.
Table Mappings
Table mapping uses several types of rules to specify the data source, source schema, data, and any transformations that should occur during the task. You can use table mapping to specify individual tables in a database to migrate and the schema to use for the migration. The table and columns are defined in the metadata project. We modify this metadata using table_mappings.py.
SCN Column
An additional column (SCN) is added to each table. This is the Oracle System Change Number and can be used to determine the order in which changes were made to the source database.
This is only populated for CDC updates. The values are taken from the source table header (AR_H_STREAM_POSITION) and added using a transformation rule in
table_mappings.py.
The first 16 characters with the '.' removed is the hexadecimal value of the SCN.
Materialised Views
This is a workaround for tables which have incompatible column types. The columns are excluded in materialised views on the source database. The names of the materialized views are modified to remove the _MV suffix so they match the name of the original tables.
LOB
Large Objects (LOBs) are a set of data types that are designed to hold large amounts of data (see LOB Intro). We exclude any columns of BLOB-type. We truncate columns of CLOB-type (see ###data-truncation) which means the data could be corrupted.
Standalone Scripts and Lamdba Functions
Validating a full load task
validate_full_load.py is a standalone script for checking a full load task (or
the full load part of a combined full load and CDC task) has collected all the
rows of the tables. It compares the table statistics from the full load task
with the size of the tables in the source database.
You'll need to run it after a full load task completes. Where possible, recovery should still be disabled on the source database. This will ensure no further rows have been added since the full load ran.
Before running the script, you'll need to edit it to set the location of your database credentials files.
Then run it with 2 to 4 command-line arguments:
- required: the name of the json file containing your database login credentials (for example 'delius_sandpit' - no need for .json)
- required: the identifer of the replication task to get the row counts from
- optional: add --save if you want to save the output - it will go in a file called 'validation-results-[date].json'
- optional: add --include-cdc if you want to compare counts to the total rows rather than just the full load rows (total rows are calculated as full load rows plus CDC inserts, minus CDC deletions)
So overall you'll end up with a command like:
python validate_full_load.py delius_sandpit delius-0-0-full-load-eu-west-1-preprod --save --include-cdc
Data truncation
In limited LOB mode, you set a maximum size LOB that AWS DMS should accept. LOBs that exceed the maximum LOB size are truncated and a warning is issued to the DMS log file.
get_truncation_info.py is a standalone script for getting the following
information related to data truncation:
- number of rows affected (where values were/would be truncated given the size limit)
- total number of rows
- maximum length (the size of the largest value)
Before running the script, you may need to edit it - to set the location of your database credentials file - to modify the SQL query for selecting relevant LOBs
Run python get_truncation_info.py --help to get the usage information.
Overall you'll end up with a command like:
python get_truncation_info.py oasys_preprod 65536
or
python get_truncation_info.py oasys_preprod 65536 -f field_list.csv
depending on whether you want to provide a list of field names
(one pair of table, field per line in a CSV file)
or let the script get it from the database.
Validate AWS Lambda Function
This function is triggered whenever a new file is added to the landing bucket.
When triggered the function attempts to load the file as a
pyarrow.ParquetDataset object to verify if it is a parquet file.
If it is a non-empty parquet file and adheres to the expected metadata specified in the metadata bucket, the file is moved to the raw_hist_bucket. Otherwise it is moved to the fail_bucket.
The metadata bucket is populated by the metadata project.
How to add or update dependencies
Python dependencies (other than Python base modules, boto3 and botocore)
must be included alongside function code. These dependencies must be compiled in
an environment with the same properties as that in which the Lambda function
will be run.
To compile the dependencies, from within this directory, run:
mkdir tmp/docker run --rm -v "$PWD":/var/task lambci/lambda:build-python3.8 pip install -r /var/task/requirements.txt --target /var/task/tmpcd tmp/find . | grep -E "(__pycache__$)" | xargs rm -rftar -czvf ../dependencies.tar.gz .cd ..rm -rf tmp/
Note: the maximum size of the Lambda code AssetArchive is 69,905,067 bytes.
Created: January 9, 2024