Architecture
What does Managed Pipelines do?
The following diagram illustrates the logical architecture of Managed Pipelines.
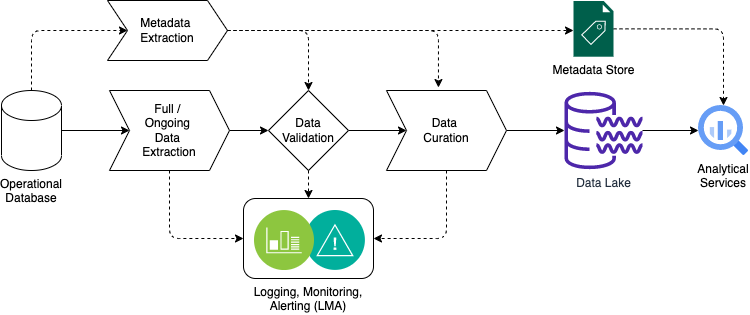
Managed Pipelines deploys infrastructure and operates Extract Transform Load (ETL) pipelines which:
- Connect to the source database
- Extract full data from the source database and then uses change data capture (CDC) to extract on-going changes. This is a very efficient way of moving data between systems and also allows downstream applications to track any changes in data
- Extract the source database metadata to be used in the rest of the pipeline and update the metadata store
- Validate the extracted data against the metadata
- Curate the data to make it convenient for analysis
- Determine which records where deleted since the last upload, in case the extraction step is unable to determine on-going changes
- Implement a Type 2 Slowly Changing Dimension (SCD2) to retain the full history of data. When a row is updated or deleted on the source database, the current record on the AP is "closed" and a new record is inserted with the changed data values.
- Upload the converted data to the Analytical Platform data lake on a daily schedule
- Expose the data and metadata for analytical services to use
- Apply Logging, Monitoring and Alerting (LMA) in accordance with good practice
How is Managed Pipelines implemented?
Managed Pipelines makes use of various serverless Data Analytics AWS Services. This means AWS takes over the heavy lifting of the following:
- Providing and managing scalable, resilient, secure, and cost-effective infrastructural components
- Ensuring infrastructural components natively integrate with each other
Managed Pipelines uses the following AWS Services:
- AWS Database Migration Service (DMS) to extract the full data and/or CDC changes from the source databases to parquet files
- AWS Lambda to validate the output data
- Amazon S3 to store the data at various stages of the pipeline
- AWS Glue Data Catalogue to expose the metadata
- Amazon Cloudwatch for logging and monitoring
- Amazon Simple Notification Service (SNS) for alerting errors to Slack
Managed Pipelines also:
- Uses create-a-derived-table to curate the data via Amazon Athena orchestrated using dbt
- Uses different AWS accounts on the Analytical Platform to facilitate and isolate resource management
- Provisions dev and preprod pipelines for testing deployment changes before deploying to production
- Extracts metadata from the source database to be used in various places along the pipeline. Please refer to metadata for more details
- Uses GitHub Actions to automate software workflows and run CI/CD pipelines. Please refer deployment for more details
- Uses pulumi to define and deploy Infrastructure as Code (IAC). Please refer to using pulumi for more details
The following diagram summarises the physical architecture for a single database and environment:
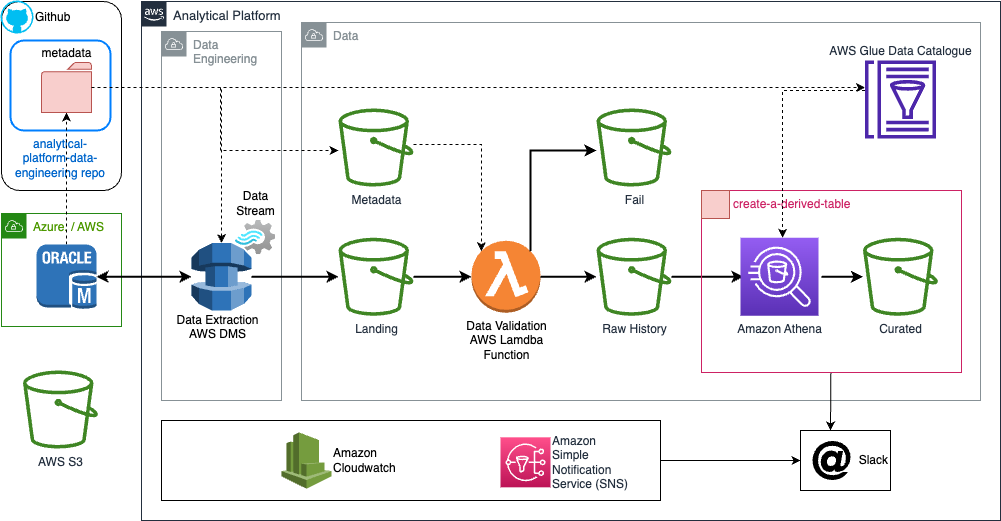
Please refer to components for a deeper dive into the individual components.
Last update:
January 9, 2024
Created: January 9, 2024
Created: January 9, 2024