Building a transaction data lake using Amazon Athena, Apache Iceberg and dbt
A goal of the UK Ministry of Justice (MoJ) is to make the justice system simpler and quicker while saving public money. The MoJ Analytical Platform supports this mission by facilitating data sharing and analysis within the MoJ, aiding better decision-making.
This post summarises how the Analytical Platform leverages Amazon Athena, along with the Apache Iceberg table format and the dbt SQL management framework, to build robust, scalable and maintainable ELT (extract, load and transform) pipelines. This approach streamlines the data lake architecture by employing the same tools for both querying and processing data. Moreover, it capitalises on the gigabyte-scale of our data, benefiting from Athena’s pricing model to significantly reduce processing costs. Note that this cost advantage may diminish for data lakes operating at the petabyte-scale.
Transaction Data Lake Architecture
Transaction data lakes combine the best features of a data lake and a data warehouse:
- The flexibility, scalability and cost-effectiveness of a data lake
- The structured data storage and processing capabilities of a data warehouse
The Analytical Platform transaction data lake architecture follows a standard ELT structure to produce cleaner, more reliable data. Data is collected in various formats from a wide range of sources, both internal and external to the MoJ, and uploaded to an S3-based data lake as Parquet files. Datasets are big but not huge, with the largest table less than 200GB (~3 billion rows) and the largest dataset less than 500GB.
The processing layer transforms the data through a series of batch procedures before writing it back to the data lake. First, the data is standardised, and Slowly Changing Dimension Type 2 (SCD2) is applied to track historical changes. Second, the data is denormalised and modelled to create the conformed layer. This makes the data easier and more efficient for users to consume. This workflow can be summarised using the Medallion architecture, in which data transitions through Bronze, Silver, and Gold layers, increasing in structure and quality at each stage:
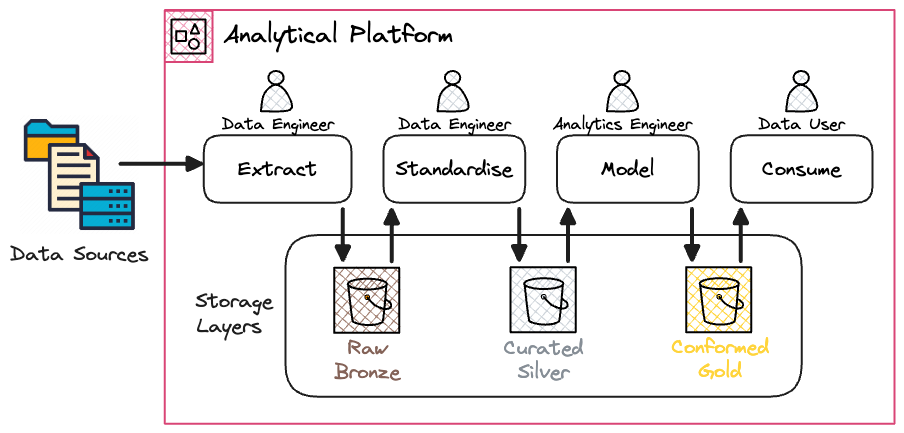
Previously, we utilised Glue PySpark to standardise the data and employed Athena for data modelling. While Glue PySpark is effective for heavy-duty data processing, it requires specialised knowledge of distributed systems for efficient use. Rising costs and recurring out-of-memory failures with the Glue jobs prompted us to reevaluate our strategy. With the release of Athena V3, it made sense to explore migrating the standardisation step to Athena as well and unify the technology stack.
Athena for data processing (Updated Nov 2024)
Amazon Athena is built on the open-source Trino SQL Engine and uses the AWS Glue Data Catalog, an Apache Hive metastore-compatible catalogue, to manage metadata for data held in S3. This allows users to interact with structured data in S3 using SQL queries. Athena is serverless and operates within a shared regional cluster, meaning all accounts in the same AWS region share the same pool of resources. It uses asynchronous processes and quotas to ensure effective and fair usage across accounts.
Although Athena is often used as an ad-hoc querying engine, it can also be used for ELT, offering several advantages:
- Serverless: No infrastructure to manage.
- Interactive and SQL-based: Easy and intuitive to use, particularly for new joiners.
- Unified Processing and Querying: Facilitates sharing best practices between data engineers and analysts, such as performance tuning, and building shared utilities.
- Automated Compute Capacity: Athena calculates the compute capacity needed to execute queries, eliminating the need for manual configuration and optimization.
- Scalable Quotas: Quotas can be increased upon request, up to a limit. This is particularly relevant for ELT processes that can take longer to run and involve hundreds of tables. For example, we extended the DML (Data Manipulation Language) query timeout from 30 minutes to 60 minutes and raised the limit on concurrent queries from 150 to 500.
- Cost-Effective: Athena’s pricing model, set at $5 per terabyte scanned, makes it highly cost-effective for transforming gigabyte-scale datasets. For instance, converting CSV files to Parquet using Athena was found to be 99% cheaper than using Glue PySpark in its default configuration.
- Provisioned Capacity: Option to scale through Athena provisioned capacity, billed based on the number of DPUs provisioned and the duration.
Despite its advantages, Athena with the native Hive table format lacks support for numerous standard database features, resulting in a pipeline that can be less robust and flexible. Using the Iceberg table format helps address this gap.
Iceberg for reliability
Apache Iceberg is an open table format designed to work with analytical engines such as Spark and Trino. It optimises data access, leading to faster query responses while enhancing data reliability and consistency.
Iceberg provides Athena with support for ACID (Atomicity, Consistency, Isolation, Durability) transactions. For instance, if a CTAS or INSERT INTO statement fails on a Hive table, it may leave orphaned data at the data location, and accessible to read in subsequent queries. In contrast, Iceberg tables are ACID-compliant, ensuring that only data from successful statements is readable.
Moreover, Iceberg allows Athena to utilise the RENAME TABLE operation. This functionality simplifies the Write-Audit-Publish (WAP) pattern, which is commonly used in data engineering workflows to ensure data quality. WAP involves writing data to a staging environment where any errors can be addressed before the data is released to users. With Iceberg, the interim table can be easily renamed once validation checks have passed, streamlining WAP for full refresh pipelines. Additionally, Iceberg’s time travel feature facilitates WAP for incremental pipelines by allowing historical data access through a FOR TIMESTAMP AS OF <timestamp> filter applied to views built on top of the source table.
Iceberg tables enables row-level updates, which is useful when applying SCD2 as it requires updating previous records that have been replaced by newer versions. We evaluated implementing SCD2 using Glue Spark with Iceberg versus Athena with Iceberg. Out-of-the-box, Athena proved significantly cheaper and faster for our data volumes, while Glue Spark encountered out-of-memory issues at the higher end of our volume range. This convinced us to migrate the ELT standardisation step from Glue Spark to Athena and Iceberg.
Whilst Iceberg improves the reliability of Athena-based ELT pipelines, Athena queries are still SQL-based which can lead to challenges in code maintenance. This is where dbt proves to be particularly valuable.
dbt for maintainability
dbt is a transformation tool that extends SQL with features commonly associated with programming languages, enabling more flexible and maintainable data transformation workflows. dbt is an extensible framework composed of multiple components. The Analytical Platform uses the following components:
- dbt-core, an open-source command line tool written in python
- dbt-athena, a dbt-maintained trusted adapter which enables dbt to work with Athena
- dbt-utils and dbt-audit-helper, dbt-maintained packages which make it easier to apply common SQL-based functionalities and validations
dbt can assure the quality of transformations through data tests, for example to check whether columns contain null values. Note that with Iceberg storing much of this information as metadata, querying it through Athena becomes practically cost-free. dbt uses the concept of threads to parallelise models that have no dependencies, which speeds up runtime. This makes it easier to take advantage of Athena’s capacity, run more queries within the concurrency quota and keep queries from being cancelled for running too long.
dbt combines SQL with Jinja, a templating language, to create macros which are analogous to “functions” in other programming languages. Macros, like functions, reduce code duplication and make it easier to unit test logic. dbt-core v1.8 introduced support for unit tests, but limited to models. There are various community-supported dbt extensions, such as dbt-unit-testing, which can unit test macros. We opted for the testing method used in dbt-utils for its simplicity and readability.
dbt uses materializations to enable different usage modes. Using views breaks down complex processes into more manageable steps, enhancing code readability and reusability. It also ensures that the source table undergoes scanning only once, thereby minimising costs. However, this must be balanced with memory usage and runtime, which can be minimised by persisting intermediate outputs to a table. While dbt-athena supports incremental materialization, which can speed-up runtime, this approach is more complex to set up and maintain. Performance testing revealed that the runtime and costs for recreating our largest table remained more effective than with the previous Glue PySpark-based solution. Consequently, we chose to initially adopt a simpler strategy and rely on the view and table materializations.
As part of migrating our standardisation step to Athena, we enhanced the Analytical Platform dbt implementation with additional features to further improve maintainability and scalability.
Model Generation
Some transformations consist of applying the same logic across multiple tables, for example when deduplicating a dataset comprised of several tables. This is often achieved by iterating through a list of tables and applying the same transformation to minimise code redundancy.
dbt follows a one-model-per-table philosophy, making it simple and intuitive. However, this approach doesn’t support looping, leading to multiple models repeating the same logic. Such redundant code is difficult to maintain because any changes to the logic needs to be replicated in multiple locations. While there has been discussions to make it possible for dbt to generate models using Jinja, this feature is still under development.
Instead, we developed a solution that generates models dynamically using Python at run time. Template .sql files are used to represent each stage of a pipeline. Table parameters are passed from either the Glue table properties or a .yaml configuration file. Models are then generated for every combination of table and template. Integration tests generate and run the models against dummy data, ensuring the templates function as expected.
Chunking
Sometimes the demands of a query exceed the resources available to the Athena cluster. One solution is to employ chunking, where the data is divided into smaller portions, making each segment quicker to execute and less memory-intensive. The transformed segment is then inserted into the final table using an INSERT INTO statement. However, this approach can involve maintaining extensive boilerplate code. To simplify this, we developed a custom insert_by_chunk dbt materialization, based on the insert_by_period materialization. After completing all the INSERT INTO operations, checks ensure that all the data has been handled accurately.
Note that each segment is executed sequentially, rather than concurrently, due to the way dbt manages materializations. However, this limitation is less critical for batch processes, where runtime is less important since they typically run overnight. Furthermore, chunking is only suitable for queries that can operate independently on each segment, without requiring access to the entire table. Finally, each segment incurs additional costs as the same data is scanned repeatedly, unless the data is partitioned by the same column used for chunking. This limitation is also less significant if the initial cost is low.
Orchestration
GitHub workflows are used to automate and orchestrate the dbt builds. Co-locating the SQL and automation code enhances transparency and simplifies maintenance. We also added several features to facilitate early error detection and automated recovery:
-
A development GitHub workflow which is triggered when a pull request is raised. This workflow selectively builds new or updated models and their children in a development environment, making it easier for users to review the transformation prior to deploying to production.
-
Integrating Slack notifications into our production workflows to promptly alert stakeholders in the event of model or validation failures.
-
Incorporating a retry mechanism into our production workflows with custom logic. This feature identifies and automatically reattempts failed models and their children, which is particularly useful for resolving errors stemming from transient issues.
Enhancing observability (Added Nov 2024)
As part of our ongoing efforts to enhance our technology stack, we are looking to improve Athena and data usage observability. Currently, Athena query-related metrics are published to Amazon CloudWatch, enabling us to monitor metrics such as the volume of data processed and the number of failed queries at an aggregate level. This makes it possible to understand resource consumption and receive early warning signs that Athena usage is approaching resource limits, giving us more time to take corrective action.
Unfortunately, this approach has limitations, especially when it comes to monitoring user-level activity as well as data and table usage. Therefore, we are considering the option to publish Athena and Glue CloudTrail events to S3, derive custom metrics using dbt, and visualize them with Amazon Managed Grafana. Amazon Managed Grafana provides a fully managed service for creating, sharing, and exploring dashboards, allowing us to gain deeper insights into our logs and correlate it with data from other services across the MoJ AWS estate.
Bringing it all together
We previously utilised Athena alongside Glue PySpark for our ELT pipelines. Migrating from Glue PySpark and Hive to Athena v3, Iceberg, and dbt has resulted in an impressive 99% reduction in individual query costs. This cost efficiency has enabled us to switch from weekly to more frequent daily refreshes while also onboarding new pipelines. Notably, we have still managed to achieve substantial savings, as shown in our monthly service cost graph:
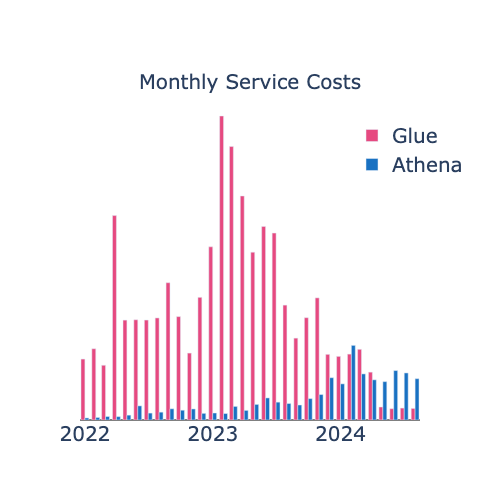
In addition, the runtime for the longest jobs has decreased by 75%, and intermittent failures due to insufficient resources have become extremely rare. During the migration, we took the opportunity to enhance our dbt solution by integrating features that improve both maintainability and data quality. This includes dynamically generating models and implementing a Write-Audit-Publish (WAP) pattern. These improvements ensure that our analysts have more timely access to large datasets, and to work more efficiently on a reliable and maintainable platform.
Furthermore, the unification of the data processing tools streamlines our technology stack and fosters a culture of collaboration within our data teams, making it easier to share enhancements and best practices. Looking ahead, we are excited about the potential to further innovate and refine our analytics capabilities, ensuring we continue to deliver greater value to the justice system.
Acknowledgements
I would like to thank the following individuals for their invaluable contributions to the technical solution:
- Gwion Aprhobat
- Siva Bathina
- David Bridgwood
- Jacob Hamblin-Pyke
- Tom Holt
- Matt Laverty
- Theodore Manassis
- William Orr
I would also like to thank the following individuals for their insightful feedback and editorial assistance:
- Jeremy Collins
- Tom Hepworth
- Thomas Hirsch